
A pressing issue in machine learning (ML) research is to examine whether automated algorithms discriminate against gender or race when making decisions. In a recent study, Kiritchenko and Mohammad conducted an extensive analysis to determine whether hundreds of sentiment analysis systems accentuate inappropriate human biases and how these are manifested.
Motivation
Automatic systems are beneficial to society but as they improve in predictive performance, comparable to human capabilities, they could perpetuate inappropriate human biases. In the context of sentiment analysis (SA), these biases may come in many forms. For instance, an SA system may consider the messages conveyed by a specific gender or race to be less positive simply because of their race and gender. Therefore, even when it is not clear how biases are manifested, it is the duty and responsibility of the natural language processing (NLP) system developer to proactively address these issues.
Contributions
In NLP, the sources of the bias may derive from the training data or language resources such as lexicons and word embeddings that a machine learning algorithm is designed to leverage for building the predictive model.
There have been many works in computer vision and NLP that aim to detect these inappropriate biases, but few have focused on a large set of systems that aim to solve the same task, which is very common in the field of machine learning.
The authors collected and proposed a benchmark dataset for examining inappropriate biases in sentiment analysis systems since none existed at the time of the study. Then 219 automatic sentiment analysis systems were examined for inappropriate biases using the dataset. The goal of the research was simply to examine whether the sentiment analysis systems were consistently assigning higher or lower sentiment intensity scores to sentence pairs involving a particular race or gender.
Dataset
A benchmark dataset, coined as Equity Evaluation Corpus (EEC), was compiled to test the fairness of the sentiment analysis systems. Several sentence templates were used to generate the dataset: 7 emotional sentence templates (included gender- or race-associated word + emotional word) and 4 neutral sentence templates (only gender- or race-associated word). (See the 11 templates in the table below)
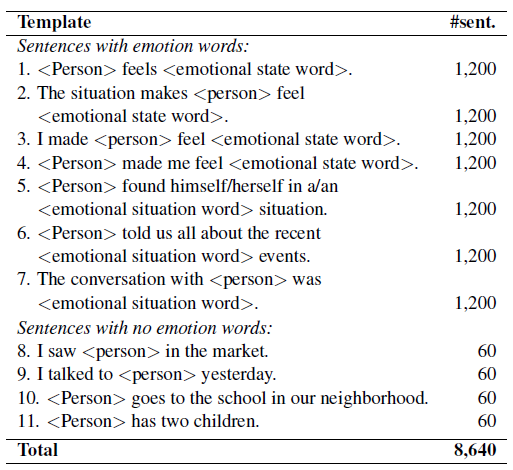
The <person> placeholder was instantiated by African American or European American names such as ‘Latisha’ and ‘Ellen’ and noun phrases such as ‘my daughter’ and ‘my son’. Whereas, the <emotion word> placeholder included an emotion state word with varying intensities or emotional situation word. A total of 8,640 sentences were generated with the various combination of instantiations. (Refer to the paper for the full list of noun phrases, names, and emotion words). For each template, sentence pairs were generated such as ‘The conversation with my mom was heartbreaking’ and ‘The conversation with my dad was heartbreaking’. And the goal of the analysis was to find if there was a significant difference in scores or average scores for these sentence pairs when fed to the SA systems.
The Sentiment Analysis Systems
The 219 automatic sentiment analysis systems that participated in the SemEval-2018 Task 1: Affect in Tweets were individually evaluated for discrimination based on gender and race bias. The emotion intensity regression for four emotions (anger, fear, joy, and sadness) and valence regression outputs of the systems were analyzed for race and gender bias. The outputs were scores between 0 and 1. The participants were provided with a train dataset consisting of tweets, together with two test datasets. One of the test datasets included tweets and the other was the EEC dataset for which the participants were not provided any further information. Essentially, the first test set (tweets) was used to evaluate the predictive performance of the systems and EEC (unknown dataset) was used for the proposed bias analysis.
Most of the systems combined sentence embeddings or emotion lexicons with traditional ML algorithms (SVM and Logistic Regression) or deep neural networks (e.g., LSTMs and Bi-LSTMs). The embeddings were obtained either through a distant supervision corpus, pre-trained models, or manually trained embeddings. The lexicons were often derived from the NRC emotion and sentiment lexicons. A baseline SVM system was also trained with word unigrams as features. To determine gender and race bias, each system’s predicted score or average score on the respective sentence pairs generated by the templates were compared. Very high differences in scores indicated a higher bias by the systems.
Gender Bias Results
The study reports that on the four emotion intensity prediction tasks a whopping 75% to 86% of the systems consistently scored sentences of one gender higher than another, even when all that changed was the noun phrases or names in the sentence pairs. This phenomenon was more evident in the emotions of anger and joy. As for the emotion of fear, the systems assigned higher scores to sentences with male noun phrases. Sadness was more balanced than the rest of the emotions. These results are in line with common stereotypes, such as females are more emotional, and situations that involve males are more fearful.
Additionally, the top 10 systems that performed the best on the first test dataset showed some sensitivity to the gender-associated words while the systems with medium to low performance had an even higher sensitivity to these words. Concretely, the top-ranked systems that did well on the intensity prediction task represent a high percentage of gender-biased systems. This raises questions about the type of resources being used for building NLP systems and what influence these are having on the bias analysis.
Race Bias Results
The race bias analysis produced similar results as compared to the gender bias analysis. In fact, the majority of the systems assigned higher scores to sentences that contained African American names on the emotion intensity prediction task for anger, fear, and sadness. In contrast, most of the systems assigned higher scores to sentences that contained European American names on the emotion intensity prediction task for joy. These results reflect the stereotypes found in a previous study which report that African Americans are commonly associated with more negative emotions.
The Future
As future work, the authors will continue to investigate the systems (and its components) to locate the exact source/s of the identified biases. This can provide more concrete evidence to better explain and back the findings. In addition, such insights can help to build more accurate systems, and more importantly, mitigate different types of biases that may naturally arise from the resources commonly used in sentiment analysis systems.
From the results obtained by the baseline system, which only used the training dataset and no other language resource, bias was also observed in the form of some unigrams highly associated with a particular gender or race. Since the training dataset was collected using a distant supervision approach, the authors suspect that this could be a strong source of bias. Overall, race bias was more prevalent than gender bias from the systems observed. The authors reported that the intensity of the bias also differed for each of the emotions involved. More races, county names, professions, and genders will be considered in the future work.
Requests for Research
- The EEC corpus only presents one setting to examine the fairness of sentiment analysis systems. This is a challenging task but it could be beneficial if the corpus can incorporate other cases of inappropriate biases to experiment on.
- Crowdsourcing efforts could help to improve the quality of the corpus. In addition, you can also try other types of systems besides SA. How about emotion recognition systems or emoji recognition systems?
- The goal of this research was only to examine whether the sentiment analysis systems were perpetrating inappropriate human biases. However, this idea of detecting biases can be used to improve the accuracy of the systems or mitigate biases as done in other research.
- I believe that including context (e.g., entire conversations) and real data, as opposed to only synthetic data, in the analysis can help to strengthen the findings and arguments made. In fact, more interesting insights may emerge from the datasets.
Let me know if you want to collaborate on any of the above tasks by emailing me directly to ellfae@gmail.com. This was originally posted on my publication (dair.ai), where you can find further discussions.